|
在识别内容1的时候,我就已经构建了标签树,那么我的内容1实际上已经被标签树拆解为由段落组成的树状结构了。
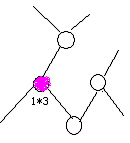
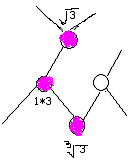
上图是内容1的标签树。在这里,我遇到一个问题,那就是针对标签树权重赋值的时候,应该是面向整个页面的标签树,还是仅仅面向内容1的标签树的? 很多朋友可能会认为,既然是针对内容1的关键词进行赋值判断,那只处理内容1就好了。其实不然。一款搜索引擎,其处理的数据少说也要千万级别的,所以搜索引擎对于高效率的代码与算法要求是极高的。 而正常情况下,一个网站的网页是不可能孤立存在的,在对一个页面针对某一个关键词进行排序的时候,除了要考虑站外因素外,我需要考虑站内权重的继承,那 么在考虑站内权重继承的时候,我必然避不开内链的计算,同时内链本身也应该有不同的权重区分,而内链权重计算时,我肯定要考虑其所在页面与其相关性。既然 如此,我就应该一次性对整个页面所有的信息块进行权重分配,这样才是高效率,同时也充分体现了内容与链接相关性的重要性。用一句大家常能在网上看见的话来 说,就是相关性决定了链接投票的有效性。 好,既然确定下是整个标签树进行权重赋值,那么下面开始。 首先,我要确定重要关键词的词库。重要关键词的确定通过两种方法: 1.不同行业的重点关键词。 2.针对句子结构与词性的重点关键词。 每一款较为成熟的商业搜索引擎,针对不同行业,其算法都会有所不同。而行业的判断,就是依托于各个行业的关键词库进行的。最近百度针对一些特定关键词,在搜索结果中返回网站的备案信息和认证信息,由此可见,词库其实早已存在。 那么,句子结构又从何说起呢?中文句子不外乎主谓宾定状补几个结构组成,而词性也仅有名词、动词、介词、形容词、副词、拟声词、代词、数词。相信很多人 刚做SEO的时候,肯定听说过搜索引擎除噪的时候,会去掉的地得和代词,其实这种说法大面上对,但也并非完全准确。从根本原理来说,是针对句子结构与词性 而给予处理时的态度不同。我们可以肯定,主语一定是最重要的部分,往往一句话主语变了,其针对的事物和所要表述的意义也就往往不同。而针对的事物若有变 化,极有可能导致这篇文章所涉及的行业有所变化。故而,主语肯定是我所需要的重点词。这里为什么我没有说在主语部分去掉代词呢?因为往往去掉主语会使得句 子失真,所以我要保留主语所有属性的词,即便是看起来没有意义代词。 那么定语呢?往往定语决定了一个事物的程度或性质,所以定语也很重 要。但问题就来了,对于用户来说,美丽的画与漂亮的画是同一个意思,而美丽的画与难看的画却是相反的意思。同时其它句子结构例如补语作为句子的补充,往往 承载了地点、时间等信息量,那也很重要。若是如此,那我又要如确定我认为最主要的关键词呢? 这个问题确实很复杂,但其实能够解决它的办 法既简单又困难。那就是时间与数据的积累。也许有人会觉得我这么说是不负责任,但事实却是如此。倘若这个世界上没有SEO、没有伪原创,那么搜索引擎可以 高枕无忧,因为没有伪原创的干扰,搜索引擎可以迅速的识别出转载内容,然后非常轻松的计算排名。但有了伪原创之后,其实每一次内容判断算法的调整,更多的 是对目前一些常见的伪原创做法进行识别。正因为有伪原创的存在,如果是我设计策略,我会设计出两个词库,词库A是用于区分内容所从属的行业,词库B则是针 对不同行业,然后在设置若干规则与这两个子词库进行关联。 举例。比如伪原创猖獗的医疗SEO,通过一些病种词,可以迅速识别出其内容属 于医疗行业。那么在选择的时候,鉴于某些原因,我将严厉对待医疗,则我认为医疗文章内容重要的仅仅是充当主语的名词,然后在充当主语的名词中,病种名词作 为最优先,进而进行优先级排序,在排序中若主语名词数大于N,则按照其所处的信息块距离根节点最近最有先原则,并且同一名词仅选择一次,然后选取前N个重 要关键词作为赋值的初始节点,进行权重赋值。 那么在赋值的时候,我设定赋值系数e,我可以判断在这几个被赋值的节点上,根据关键词种类来确定赋值的比重。比如与title中重复的病种名词,其对应的系数为e1,与title中不对应的病种名词系数为e2,其它名词系数为e3。然后我开始遍历标签树。 整个页面自身权重为Q,按照前N个关键词的顺序依次遍历。那么我的遍历原则如下: 1.第一次遍历时,第一个重要节点权重值为Qe1,其父节点权重值为Qe1*b,其子节点权重值为Qe1*c,然后以此原则继续遍历父节点的父节点及其父节点的子节点和子节点的子节点及其子节点的父节点。 以下举例。假定Q为1,e1为3 则一开始如下图
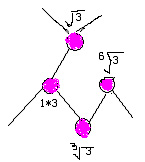
然后假定a为上一个数的平方根,b为上一个数的立方根。则如下图
接着开始遍历其它节点。
当整个网页标签树的所有节点全部被赋值后,第一次遍历结束。这时候开始第二次遍历,注意这时候与e2相乘的就不是Q了,而是第二个重要关键词所在节点的当前权重值。 这样经过N此遍历,每一个信息块都会有自己相对应的权重数值,然后我单独提取内容1的信息块,具体上文中有画图,在此就不再多画了。将内容1量化。量化 后,我就能够得到上文中我所需要的权重特征值T={t1,t2,……,tn}。由此,这个算法层就首位相应的完善了。量化公式很多,我在此就不举例了,因 为这个举例毫无意义,我又不是真写搜索引擎。 *******拓展阅读3开始************************************ (责任编辑:laiquliu) |